
 Roles and Responsibilities")
Have you ever wondered who keeps your favorite apps running smoothly 24/7, even during peak traffic? Behind every seamless digital experience stands a Site Reliability Engineer (SRE), the unsung hero bridging the gap between software development and IT operations.
In today’s hyper-connected digital landscape, where 60% of organizations experienced at least one major outage in 2026, according to the Uptime Institute, the role of Site Reliability Engineers has never been more critical. As businesses increasingly rely on complex, distributed systems to deliver services, SREs have evolved from firefighters managing incidents to strategic architects of reliability.
This comprehensive guide explores the multifaceted roles and responsibilities of Site Reliability Engineers, revealing how these technical professionals ensure your systems remain reliable, performant, and scalable. Whether you’re considering an SRE career, hiring for your team, or simply curious about this transformative discipline, you’ll discover the essential duties, skills, and practices that define modern Site Reliability Engineering.
From managing Service Level Objectives to automating infrastructure and conducting blameless post-mortems, we’ll unpack everything you need to know about what SREs actually do, and why their work matters more than ever in 2026.
Table of Contents
- Understanding Site Reliability Engineering: The Foundation
- Core Roles and Responsibilities of a Site Reliability Engineer
- Essential Skills and Technical Competencies for SREs
- SRE vs DevOps vs Traditional Operations
- Career Path and Growth Opportunities
- Common Challenges Faced by SREs
- Future of Site Reliability Engineering
- Conclusion
- Frequently Asked Questions
Understanding Site Reliability Engineering: The Foundation
Site Reliability Engineering (SRE) is a discipline that applies software engineering principles to infrastructure and operations problems. Pioneered by Google in 2003, SRE represents a fundamental shift in how organizations approach system reliability, moving from reactive firefighting to proactive engineering.
|
“SRE is what happens when you ask a software engineer to design an operations function.” Ben Treynor Sloss, |
 |
At its core, SRE is about building and running large-scale, distributed systems that are reliable, efficient, and scalable. Unlike traditional operations roles that focus solely on keeping systems running, SREs treat operations as a software problem. This means writing code to automate manual tasks, designing systems for reliability, and using data-driven approaches to improve service quality.
The philosophy behind SRE centers on several key principles: accepting that failure is inevitable, quantifying reliability through Service Level Objectives (SLOs), using error budgets to balance innovation with stability, and eliminating toil through automation. According to the 2025 SRE Report by Catchpoint, organizations implementing SRE practices report significant improvements in system uptime, faster incident resolution, and better alignment between development and operations teams.
What makes SRE particularly powerful is its emphasis on measurable outcomes. Rather than vague goals like “maximize uptime,” SREs work with concrete metrics, error budgets, and well-defined service levels that balance business needs with engineering realities. This data-driven approach enables organizations to make informed decisions about when to focus on new features versus reliability improvements, a balance that has become increasingly critical as digital services become central to business success.
Core Roles and Responsibilities of a Site Reliability Engineer
The heart of Site Reliability Engineering lies in its diverse and technically demanding responsibilities. SREs wear multiple hats, combining deep technical expertise with strategic thinking to ensure systems remain reliable, performant, and resilient. Let’s explore the fundamental duties that define this critical role.
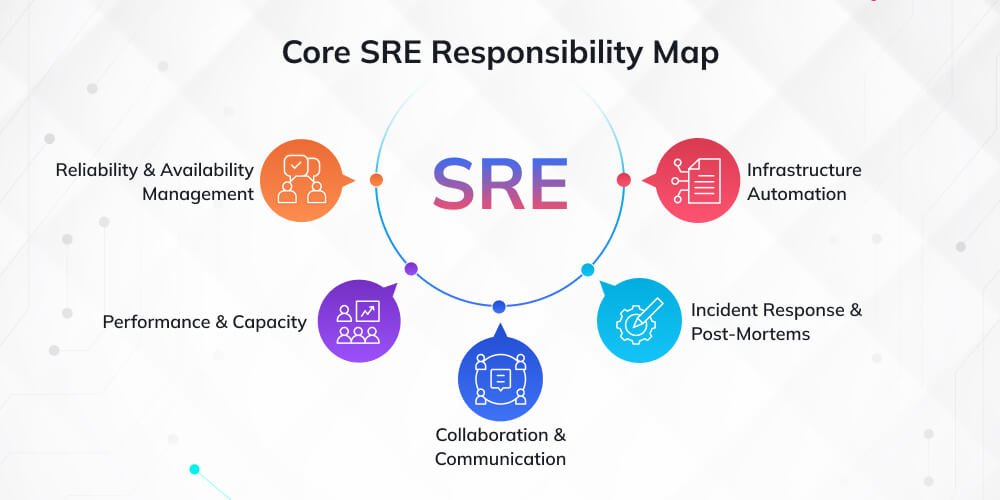
System Reliability and Availability Management
The primary responsibility of any SRE is to ensure that systems meet defined reliability targets. This goes far beyond simply keeping servers running; it’s about establishing and maintaining a robust framework of reliability metrics aligned with business objectives.
Service Level Indicators, Objectives, and Agreements: SREs define and monitor Service Level Indicators (SLIs), quantifiable measures of service quality, including latency, error rates, and system throughput. These SLIs underpin Service Level Objectives (SLOs), which set targets for acceptable service performance. For example, an SRE might set an SLO requiring that 99.9% of API requests complete within 200 milliseconds.
According to research from Catchpoint, 53% of organizations now agree that “slow is the new down,” recognizing that poor performance is as damaging as complete outages. This shift has elevated the importance of performance-focused SLOs beyond traditional uptime metrics.
Error Budgets and Reliability Targets: One of SRE’s most innovative concepts is the error budget, which defines the acceptable level of unreliability for SLOs. If your SLO guarantees 99.9% uptime, your error budget is 0.1%, which equates to approximately 43 minutes of downtime per month. Error budgets create a framework for balancing feature velocity with stability. When error budgets are healthy, teams can move faster with deployments; when budgets are exhausted, the focus shifts to reliability improvements.
Monitoring and Incident Response: SREs implement comprehensive monitoring systems to track system health in real-time. This includes setting up alerts for SLO violations, investigating anomalies, and responding to incidents when they occur. The goal isn’t just a reactive response; it’s proactive detection and prevention of issues before they impact users.
Infrastructure Automation and Configuration Management
Automation is the lifeblood of effective Site Reliability Engineering. SREs recognize that manual, repetitive tasks (known as “toil”) don’t scale and consume time better spent on strategic improvements. The 2025 SRE Report revealed that toil levels increased for the first time in five years, making automation efforts more critical than ever.
Infrastructure as Code (IaC) Implementation: Modern SREs treat infrastructure as software, managing it through code using tools like Terraform, Ansible, and CloudFormation. Infrastructure as Code enables version control, testing, and automated deployment of infrastructure changes, dramatically reducing errors and deployment time. According to Google SRE practices, IaC is fundamental to achieving reliability at scale.
CI/CD Pipeline Management: SREs design and maintain continuous integration and continuous deployment (CI/CD) pipelines that enable rapid, reliable software releases. This includes implementing automated testing, canary deployments, and rollback mechanisms. A well-designed CI/CD pipeline can reduce deployment failures by up to 70% while accelerating release frequency.
Configuration Management Systems: SREs implement and maintain configuration management systems that ensure consistency across environments. Tools like Puppet, Chef, and Salt enable SREs to manage thousands of servers with identical configurations, preventing configuration drift that can lead to outages. The goal is declarative configuration, defining the desired state of systems and letting automation handle the implementation details.
The impact of automation extends beyond efficiency. According to a DevOps survey, organizations with mature automation practices deploy 200 times more frequently than low performers, with 24 times faster recovery times and three times lower change failure rates.
| PRO TIP
Start small with automation wins: Don’t try to automate everything at once. Identify the most repetitive, error-prone manual tasks and automate those first. Build momentum with quick wins, then expand your automation scope systematically. |
Performance Monitoring and Optimization
In an era where “slow is the new down,” performance optimization has become a core SRE responsibility. Users expect instant responses, and even slight degradations can trigger abandonment and revenue loss.
Application Performance Monitoring (APM) Tools: SREs implement comprehensive observability platforms using tools like Prometheus, Grafana, DataDog, and New Relic. According to Grafana Labs’ Observability Survey, teams are juggling dozens of tools and data sources to achieve comprehensive system visibility. Modern APM goes beyond simple metrics collection, incorporating logs, traces, and events to provide holistic system understanding.
Capacity Planning and Scaling: Effective SREs anticipate growth and plan capacity accordingly. This involves analyzing traffic patterns, predicting resource needs, and implementing auto-scaling strategies that adjust resources dynamically. Capacity planning prevents both over-provisioning (wasting resources) and under-provisioning (risking outages during traffic spikes).
Performance Tuning Methodologies: SREs continuously optimize system performance through profiling, benchmarking, and systematic improvement. This includes database query optimization, caching strategies, CDN configuration, and code-level improvements. Performance optimization is never “done,” it’s an ongoing cycle of measurement, analysis, and refinement.
The business impact of performance work is substantial. Studies show that a 100-millisecond delay in page load time can reduce conversion rates by 7%, while pages loading in 5 seconds versus 2 seconds experience 70% longer average sessions.
Incident Management and Post-Mortem Analysis
Despite best efforts, incidents will occur. How teams respond to and learn from incidents defines organizational resilience and long-term reliability.
On-Call Rotations and Escalation: SREs participate in on-call rotations, serving as first responders when systems experience issues. According to the SRE Report, on-call practices have remained largely consistent, with most teams allocating significant time to rotation schedules. Effective on-call management includes clear escalation paths, adequate rest periods, and fair rotation schedules that prevent burnout.
Blameless Post-Mortems: One of SRE’s most valuable cultural contributions is the blameless post-mortem. After incidents, teams conduct structured reviews focused on systemic issues rather than individual fault. According to Google’s SRE Workbook, blameless post-mortems create a culture of continuous improvement where teams learn from failures without fear of punishment.
A comprehensive post-mortem includes: timeline of events, root cause analysis, impact assessment, contributing factors, lessons learned, and action items with assigned owners. The goal isn’t just documentation, it’s preventing recurrence through systematic improvements.
Root Cause Analysis Frameworks: SREs use methods such as the “Five Whys” and fishbone diagrams to identify root causes rather than superficial symptoms. This deep analysis ensures that remediation efforts address the root causes rather than symptoms. Research shows that organizations practicing thorough root cause analysis reduce repeat incidents by up to 80%.
Collaboration and Cross-Functional Communication
SREs don’t work in isolation, they serve as bridges between multiple teams and stakeholders, translating technical concepts for business audiences and business needs for technical teams.
Working with Development Teams: SREs collaborate closely with software engineers to design reliable systems from the start. This includes reviewing architecture designs for reliability, providing feedback on deployment strategies, and sharing operations knowledge. The partnership between SREs and developers ensures that reliability is built in, not bolted on.
Bridging Operations and Software Engineering: The traditional wall between “dev” and “ops” has proven dysfunctional in modern, fast-moving organizations. SREs break down this barrier by speaking both languages, understanding business requirements while maintaining deep technical expertise. This translation capability makes SREs invaluable in aligning technical work with business objectives.
Documentation and Knowledge Sharing: SREs create and maintain comprehensive documentation including runbooks, architecture diagrams, and troubleshooting guides. Effective documentation reduces cognitive load during incidents, enables faster onboarding, and preserves institutional knowledge. According to industry research, teams with mature documentation practices resolve incidents 40% faster than those relying on tribal knowledge.
KEY TAKEAWAYS
|
Essential Skills and Technical Competencies for SREs
Success as a Site Reliability Engineer requires a unique blend of software engineering expertise, systems knowledge, and operational experience. Let’s explore the critical skills that distinguish exceptional SREs.
Programming and Scripting Skills
SREs must be proficient programmers capable of writing production-quality code. Common languages include Python (for automation and tooling), Go (for high-performance services), Bash (for scripting), and, increasingly, Rust for systems programming. The ability to read, review, and contribute to application code is essential for understanding system behavior and implementing reliability improvements.
Cloud and Infrastructure Knowledge
Modern SREs must understand cloud platforms (AWS, Google Cloud, Azure), container orchestration (Kubernetes, Docker), networking fundamentals, storage systems, and database technologies. As systems become increasingly cloud-native, expertise in distributed systems, microservices architecture, and service mesh technologies has become essential.
According to the tack Overflow Developer Survey, SRE roles consistently rank among the highest-paid technical positions, with average salaries around $130,000-$167,000 in the United States, reflecting the demand for these specialized skills.
Monitoring and Observability Tools
SREs must master observability platforms, including Prometheus, Grafana, ELK stack (Elasticsearch, Logstash, Kibana), Datadog, New Relic, and cloud-native monitoring solutions. Understanding the three pillars of observability, metrics, logs, and traces, and how to correlate them for comprehensive system understanding, is fundamental.
SRE vs DevOps vs Traditional Operations
Understanding how SRE relates to other disciplines clarifies its unique value proposition.
DevOps is a cultural philosophy and set of practices that emphasize collaboration, automation, and continuous delivery throughout the software lifecycle. It’s about breaking down silos and fostering shared responsibility.
SRE is a specific implementation of DevOps principles with a strong focus on reliability as a measurable outcome. As Google describes it, “class SRE implements DevOps.” SRE provides concrete practices, tools, and metrics for achieving DevOps goals.
Traditional Operations focuses primarily on keeping systems running, often through manual intervention and ticket-based workflows. Operations teams typically have separate goals and incentives from development teams.
The key distinction: SRE focuses on the delivery and stability of production environments using software engineering approaches, while DevOps encompasses the entire application lifecycle. SRE teams measure success through SLOs and error budgets, while DevOps teams measure success through deployment frequency and change lead time. According to Atlassian’s comparison, businesses don’t have to choose between SRE and DevOps; they’re complementary approaches that can coexist and reinforce each other.
Career Path and Growth Opportunities
The SRE career path offers clear progression and lucrative opportunities. Entry-level SREs typically start with foundational roles focusing on monitoring, basic automation, and on-call responsibilities. Mid-level SREs design and implement reliability systems, lead incident responses, and mentor junior team members.
Senior SREs architect organization-wide reliability strategies, define SLO frameworks, and influence product decisions based on reliability concerns. Staff and Principal SREs operate at the strategic level, setting technical direction, establishing best practices, and representing reliability across executive leadership.
Alternative career paths include transitioning to Platform Engineering (building developer-facing infrastructure), moving into Engineering Management, or becoming specialized consultants helping organizations adopt SRE practices. The future looks bright for SREs, with demand projected to grow 30% over the next five years according to industry forecasts.
Common Challenges Faced by SREs
Despite the rewarding nature of SRE work, professionals face significant challenges:
- Balancing Innovation vs. Stability: Organizations often pressure SREs to prioritize feature releases over reliability. The 2025 SRE Report found that 41% of respondents reported being pressured “often” or “always” to prioritize release schedules over reliability, underscoring the ongoing tension between agility and stability.
- Toil Management: For the first time in five years, toil levels increased in 2024, with the median time spent on operations rising from 25% to 30%. Managing and reducing toil while maintaining system reliability remains an ongoing challenge.
- Alert Fatigue and On-Call Stress: Constant alerts and irregular on-call hours can lead to burnout. According to the 2025 SRE Report, stress levels often remain elevated even after incidents are resolved, underscoring the need for stronger post-incident support.
- Tool Sprawl Complexity: While teams typically use 2-10 monitoring tools, managing this complexity while maintaining comprehensive observability remains a challenge.
- Solution Approaches: Successful SREs address these challenges through automation, clear SLO frameworks, rotation management, psychological safety initiatives, and executive buy-in for reliability investments.
| AVOID THIS MISTAKE
Treating SRE as “glorified ops”: Organizations that view SRE as simply rebranded operations miss the transformative potential. SREs are software engineers who happen to focus on reliability. Why it’s problematic: This mindset prevents SREs from writing code, automating toil, and driving systematic improvements, resulting in expensive operations teams without the engineering leverage that makes SREs powerful. What to do instead: Ensure SREs spend at least 50% of their time on engineering work (automation, tooling, system design) rather than operational toil. Measure and enforce this balance. |
Future of Site Reliability Engineering
The SRE discipline continues evolving rapidly. Key trends shaping the future include:
- AI and Machine Learning Integration: AI-driven incident detection, automated root cause analysis, and predictive capacity planning are emerging capabilities. However, the 2024 DORA Report cautions that AI expedites valuable activities but may paradoxically increase toil if not implemented thoughtfully.
- Platform Engineering Convergence: SREs increasingly focus on building self-service platforms that empower developers to own reliability while reducing operational burden.
- Security Integration (SRE + SecOps): As security becomes integral to reliability, SREs expand responsibilities to include security monitoring, compliance automation, and secure deployment practices.
- Observability Evolution: From traditional metrics to advanced observability, incorporating business outcomes, user experience, and predictive analytics.
- FinOps Collaboration: As cloud costs rise, SREs partner with finance teams to optimize infrastructure spend without sacrificing reliability.
The demand for skilled SREs shows no signs of slowing. Organizations recognize that reliability is a competitive differentiator, making SRE expertise increasingly valuable.
Conclusion
Site Reliability Engineers sit at the intersection of software engineering and operations, turning reliability into an engineered capability rather than a reactive firefight. From defining and managing SLOs to automating infrastructure, optimizing performance, and leading incident response, SREs own the practices that keep modern, distributed systems fast, available, and scalable. Their impact is measured not just in uptime, but in customer trust and business continuity.
As more organizations recognize reliability as a competitive advantage rather than a cost center, the demand for skilled SREs will only intensify. Building the right blend of coding skills, cloud and observability expertise, and calm, data-driven incident leadership is no longer optional if you want to grow in this field. If you’re ready to formalize those skills and move into an SRE role, structured learning helps. Exploring our DevOps Certification courses is a practical next step to turn this role description into your career reality.
Frequently Asked Questions
1. What is the primary difference between an SRE and a DevOps Engineer?
SRE focuses on the reliability and stability of production systems, using measurable objectives such as SLOs and error budgets. At the same time, DevOps is a broader cultural philosophy encompassing the entire software delivery lifecycle. SRE is often described as a specific implementation of DevOps principles with strong emphasis on engineering practices for reliability.
2. What programming languages should I learn to become an SRE?
The most valuable languages for SREs are Python (for automation and tooling), Go (for high-performance tools and services), Bash (for scripting), and, increasingly Rust for systems programming. Additionally, you should be comfortable reading code in whatever languages your organization’s applications are written in.
3. How much coding do SREs actually do compared to operations work?
Google’s SRE model recommends SREs spend at least 50% of their time on engineering work, writing code, building tools, automating systems, rather than operational toil. When operational work exceeds this threshold, organizations should add more SREs or reduce toil through automation.
4. What is an error budget and how does it work?
An error budget is the acceptable amount of unreliability derived from your Service Level Objective. If your SLO promises 99.9% uptime, your error budget is 0.1% (about 43 minutes of downtime monthly). This budget balances innovation velocity with stability—when the budget is healthy, teams can deploy faster; when exhausted, focus shifts to reliability.
5. Do I need a specific degree or certification to become an SRE?
While many SREs have Computer Science degrees, there’s no single required path. What matters most is demonstrating strong programming skills, systems knowledge, and operations experience. Relevant certifications include DevOps Foundation, Kubernetes Administrator (CKA), AWS/Azure/GCP certifications, and increasingly, specialized SRE training programs.
6. What is the typical salary range for Site Reliability Engineers?
According to 2024 market data, SRE salaries in the United States average $130,000-$167,000 annually, with senior roles and major tech companies paying significantly more. Salaries vary by location, experience level, and company size, but SRE consistently ranks among the highest-paid technical roles.
7. How stressful is working as an SRE with on-call responsibilities?
On-call duties are an inherent part of SRE work, and stress levels can be significant during incidents. However, well-run SRE organizations mitigate this through fair rotation schedules, comprehensive runbooks, blameless cultures, and post-incident support. The 2025 SRE Report shows that while incident stress is common, mature organizations provide better support structures.



 Cycle")








